

Data Engineering Consulting Services: What AI-Ready Data Infrastructure Looks Like in 2026

TABLE OF CONTENT
What Are Data Engineering Consulting Services?
Classic vs. AI-Ready Data Engineering: What the Stack Looks Like Now
The 6 Core Service Pillars of AI Data Engineering Consulting
MLOps Consulting: Why Data Engineering and ML Production Are Inseparable
How to Evaluate a Data Engineering Consulting Partner for AI Workloads
Conclusion

The number Gartner keeps publishing – 85% of AI projects fail because of data, not model choice – lands differently once you have seen it from the inside. Most enterprise data stacks were built to answer yesterday’s questions in a BI dashboard. They were not built to feed real-time AI inference, RAG pipelines, or agent-orchestrated workflows. The gap between what data teams built and what AI teams need is where most AI initiatives stall. Data engineering consulting services exist to close that gap. This guide explains what the modern engagement covers and how to evaluate a partner who can actually deliver it in 2026.
What Are Data Engineering Consulting Services?
Data engineering consulting services are professional services that design, build, and modernize an organization’s data infrastructure. The scope ranges from a targeted pipeline redesign to a full platform modernization. In 2026, the best engagements treat AI workloads as a first-class design requirement from day one – not something you retrofit after the warehouse is already built.
The distinction matters more than it sounds. A data stack built for business intelligence optimizes for query performance on historical structured data. A stack built for AI needs real-time streaming pipelines, vector storage for RAG retrieval, feature engineering pipelines for ML models, PII classification at ingestion, and data lineage that satisfies AI compliance audit requirements. These are different architecture choices, and making the wrong ones early costs six to twelve months of rework later.
When to Engage a Data Engineering Consulting Partner
- Your AI or ML projects are failing consistently due to data quality, availability, or pipeline gaps
- You are migrating from a legacy data warehouse to a modern lakehouse or data mesh architecture
- You need to build RAG infrastructure for an enterprise AI agent deployment
- Your pipelines cannot support real-time AI inference at production scale
- You are entering a regulated market and need compliance-grade data governance
- Your in-house team lacks vector store, MLOps, or streaming architecture expertise
Classic vs. AI-Ready Data Engineering: What the Stack Looks Like Now
| Dimension | Classic Data Engineering (2018–2022) | AI-Ready Data Engineering (2024–2026+) |
| Primary output | BI dashboards, reporting, analytics | AI agents, RAG systems, ML models, real-time inference |
| Data types | Structured (SQL, CSV, JSON) | Structured + unstructured (PDFs, emails, images, audio) |
| Processing model | Batch ETL/ELT on schedule | Batch + real-time streaming + event-driven pipelines |
| Storage | Relational databases, data warehouses | Lakehouse + vector stores + feature stores |
| Data quality focus | Schema validation, null checks, deduplication | Embedding quality, chunk coherence, label accuracy for AI |
| Governance | Access control, data catalog | + PII classification, model lineage, AI decision audit trails |
| Key skills | SQL, Spark, dbt, Airflow | + vector databases, embedding pipelines, MLOps, RAG infra |
The Databricks State of Data and AI 2026 Report found that 71% of data engineering teams are now explicitly tasked with building AI-ready infrastructure – up from 31% in 2023. Organizations that built this capability proactively are deploying AI at three times the rate of those still working from analytics-era stacks.
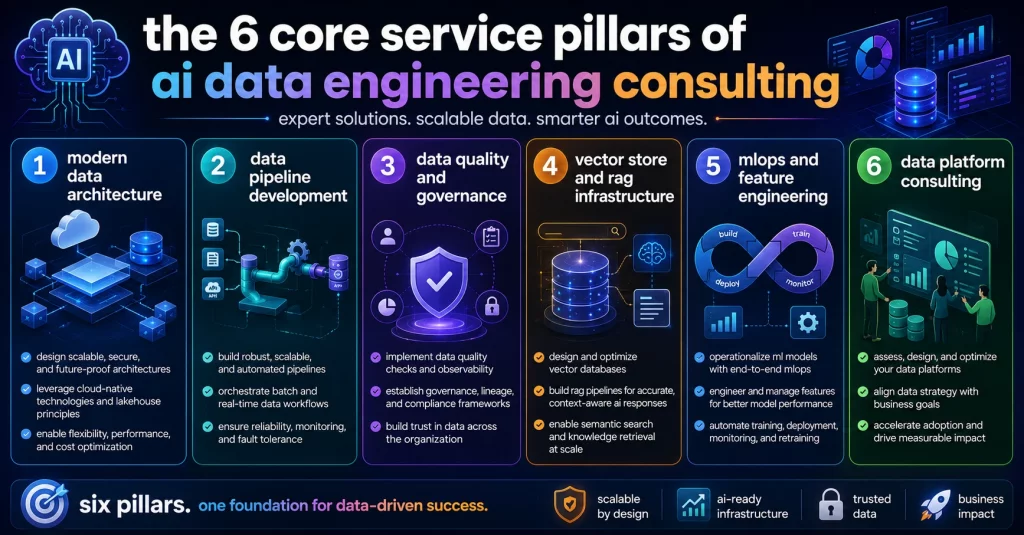
The 6 Core Service Pillars of AI Data Engineering Consulting
A comprehensive data engineering consulting engagement in 2026 spans six capability areas. Not every organization needs all six immediately – but understanding the full scope helps you identify where your stack has gaps and where to invest first.
Pillar 1: Modern Data Architecture
Architecture decisions cover the foundational choices: lakehouse vs. warehouse vs. data mesh, cloud vs. on-premise vs. hybrid, and the integration pattern connecting source systems to the data platform. Decisions made at this layer constrain what is possible in every other pillar. Picking the wrong storage model for your AI workload profile means rebuilding it later.
Pillar 2: Data Pipeline Development
Pipeline development covers batch ETL/ELT, real-time streaming (Apache Kafka, Spark Streaming, Flink), and change data capture (CDC) for operational database replication. For AI workloads, pipeline reliability and latency matter in ways they never did for BI. An AI agent making a credit decision on data that is 48 hours stale is not an AI agent – it is a time-delayed manual process.
Pillar 3: Data Quality and Governance
This pillar covers data lineage (tracking where every data point came from and how it was transformed), data observability (monitoring for anomalies and drift in production), PII detection and classification, and data catalog management. For AI systems, governance here is directly connected to compliance audit requirements. You cannot demonstrate GDPR compliance for an AI decision without lineage that traces the decision back to its input data.
Pillar 4: Vector Store and RAG Infrastructure
Building the data infrastructure that enterprise RAG systems depend on: document ingestion pipelines, embedding model selection and hosting, vector database deployment (Pinecone, Weaviate, pgvector, Milvus), and retrieval quality optimization. This is the fastest-growing area of data engineering work in 2026 and the one most traditional data engineering firms are not yet equipped to deliver.
Pillar 5: MLOps and Feature Engineering
MLOps consulting covers the operational layer for ML models in production: model versioning and registry, CI/CD pipelines for model deployment, feature store design and management, drift monitoring, and automated retraining triggers. Without MLOps, ML models degrade in production without anyone noticing until something breaks. McKinsey’s State of AI 2025 found that organizations integrating data engineering and MLOps planning reduced production ML incidents by 60–70%.
Pillar 6: Data Platform Consulting
Data platform consulting covers selection, configuration, and optimization of the core platform stack: Databricks, Snowflake, BigQuery, Microsoft Fabric, or an open-source equivalent. Platform selection has long-term cost and scalability implications. The right platform depends on your workload profile, compliance requirements, and in-house operational expertise. Choosing Databricks because it is popular is not platform consulting.
MLOps Consulting: Why Data Engineering and ML Production Are Inseparable
MLOps consulting has become a standard component of data engineering engagements for organizations running AI in production. The connection is not optional – ML models are data artifacts, and their performance is determined by the quality, freshness, and consistency of the data they are trained and scored on.
What MLOps Covers in a Data Engineering Context
- Model versioning and registry: Tracking which model version is in production, what data it was trained on, and what evaluation metrics it achieved at deployment
- CI/CD for ML: Automating the testing, validation, and deployment of model updates – the same principle as software CI/CD, with data validation gates added
- Feature store design: Centralized storage for engineered features that ensures consistent feature computation between training and production inference
- Drift monitoring: Detecting when production data characteristics diverge from training data – the most common cause of unexplained model performance degradation
- Automated retraining: Triggering model retraining when drift thresholds are exceeded, with validation gates before production promotion
The integration point between data engineering and MLOps is the feature store and the data pipeline. When these are designed together from the start, the system stays aligned across training and inference. When they are designed separately and connected later, the mismatch causes most production ML failures.
Compliance-Grade Data Engineering for Regulated Industries
BFSI, healthcare, and manufacturing organizations need data infrastructure that satisfies GDPR, HIPAA, SOC 2, and for Vietnam-based operations, AI Law 134/2025/QH15. These requirements go well beyond access controls and extend into how data moves through pipelines, how AI systems log their data access, and how lineage is maintained for regulatory review.
On-Premise and Air-Gapped Pipeline Deployment
Some data cannot move to public cloud infrastructure. Patient records, financial transaction data, and defense information must stay on controlled hardware. On-premise pipeline deployment keeps all processing within your network. Air-gapped infrastructure adds network isolation as an additional security layer. AHT Tech designs and deploys on-premise stacks using production-grade tooling – Airflow, Spark, dbt, and vector databases – running on client hardware.
PII Detection and Masking in Ingestion Pipelines
PII must be identified before data enters your analytical or AI processing layer – not after. Modern ai ready data infrastructure includes automated PII detection at ingestion using NLP classifiers that identify names, email addresses, national IDs, and health identifiers, with configurable handling: masking for analytics use cases, tokenization for joinable data, or exclusion for highest-sensitivity fields. Handling PII at ingestion prevents contamination of vector stores, feature stores, and model training sets.
Data Lineage for AI Decision Audit Requirements
GDPR Article 22 and HIPAA both require the ability to explain automated decisions and show what data contributed to them. AI data lineage means demonstrating: which training data a model used, what features were computed from what source data, and what documents a RAG system retrieved when generating a specific response. Standard catalog tools capture warehouse lineage. AI lineage requires additional instrumentation at the model serving and retrieval layer.
How to Evaluate a Data Engineering Consulting Partner for AI Workloads
Not all big data consulting services are equipped for AI-ready infrastructure. The vocabulary has shifted, but many firms are still optimizing for the analytics era. Here is how to assess whether a partner can deliver what you need.
| Evaluation Criterion | What to Ask | Red Flag to Watch For |
| Vector store and RAG experience | Which vector databases have you deployed in production? On-premise or cloud? | Cloud-only answers, or no mention of vector stores at all |
| Platform flexibility | What stacks do you work with? Are you certified across multiple platforms? | Heavy bias toward a single vendor – Databricks-only or Snowflake-only |
| Compliance track record | Which regulated industries have you delivered for? Reference available? | No regulated industry clients, no mention of compliance architecture |
| MLOps capability | How do you connect data pipelines to model training and serving in production? | No MLOps capability or routes ML work to a completely separate team |
| Delivery model options | Do you offer project-based, dedicated team, and managed service models? | Only one delivery model offered – signals inflexibility |
AHT Tech brings 18+ years of enterprise infrastructure delivery and 250+ specialists across data engineering, AI, and compliance architecture. We work across Databricks, Snowflake, open-source stacks, and on-premise infrastructure. Vector stores and RAG pipelines are standard scope in our AI data engineering engagements.
Frequently Asked Questions
What is the difference between data engineering and data science?
Data engineering builds and maintains the infrastructure that data scientists and AI systems use. Data engineers design pipelines, build data stores, and ensure quality and availability. Data scientists use that infrastructure to build models and derive insights. In most organizations, data engineering is the prerequisite that data science depends on – and the bottleneck when it fails.
What does AI-ready data infrastructure mean?
AI-ready data infrastructure is a data stack designed specifically to support AI workloads: real-time or near-real-time pipelines, vector storage for embedding-based retrieval, feature stores for ML model training and inference, and compliance-grade lineage and governance. It differs from analytics infrastructure, which optimizes for query performance on historical structured data.
How much does data engineering consulting cost?
A focused AI-readiness assessment and architecture design engagement runs $20,000–$60,000. A pipeline modernization with vector store deployment for RAG infrastructure runs $80,000–$250,000. A full enterprise data platform modernization with MLOps integration runs $300,000–$1M+. Dedicated team engagements are priced on a monthly retainer.
What is MLOps and why does it matter for data engineering?
MLOps is the operational practice for managing ML models in production. It connects to data engineering because model performance depends on data pipeline quality. Pipeline changes that alter feature distributions degrade model performance in ways that are invisible without drift monitoring. Teams that integrate data engineering and MLOps planning avoid this failure mode.
Can data pipelines be deployed on-premise for compliance?
Yes. On-premise deployment is standard practice for healthcare, financial services, and defense. Modern orchestration tools – Airflow, Prefect, Dagster – run on-premise. Vector databases – Weaviate, pgvector, Milvus – run on-premise. Technical constraints on scalability and maintenance overhead need to be part of the architecture design, not surprises discovered during operation.
Conclusion
AI-ready data infrastructure is the foundation every AI initiative depends on. Without clean, governed, pipeline-connected data, agents hallucinate, RAG systems return stale or irrelevant results, and ML models degrade in production without warning. Data engineering consulting services in 2026 build that foundation with AI workloads as the design target.
AHT Tech’s data engineering practice covers the full stack: from legacy modernization through AI-native pipeline architecture, vector store deployment, MLOps integration, and compliance-grade governance for GDPR, HIPAA, SOC 2, and Vietnam AI Law 134/2025/QH15. We work with mid-market and enterprise clients across BFSI, healthcare, manufacturing, and logistics.
What Are Data Engineering Consulting Services?
Data engineering consulting services are professional services that design, build, and modernize an organization’s data infrastructure. The scope ranges from a targeted pipeline redesign to a full platform modernization.
In 2026, the best engagements treat AI workloads as a first-class design requirement from day one – not something you retrofit after the warehouse is already built.

The distinction matters more than it sounds. A data stack built for business intelligence optimizes for query performance on historical structured data.
A stack built for AI needs real-time streaming pipelines, vector storage for RAG retrieval, feature engineering pipelines for ML models, PII classification at ingestion, and data lineage that satisfies AI compliance audit requirements.
These are different architecture choices, and making the wrong ones early costs six to twelve months of rework later.
When to Engage a Data Engineering Consulting Partner
- Your AI or ML projects are failing consistently due to data quality, availability, or pipeline gaps
- You are migrating from a legacy data warehouse to a modern lakehouse or data mesh architecture
- You need to build RAG infrastructure for an enterprise AI agent deployment
- Your pipelines cannot support real-time AI inference at production scale
- You are entering a regulated market and need compliance-grade data governance
- Your in-house team lacks vector store, MLOps, or streaming architecture expertise
Classic vs. AI-Ready Data Engineering: What the Stack Looks Like Now
|
Dimension |
Classic Data Engineering (2018–2022) |
AI-Ready Data Engineering (2024–2026+) |
| Primary output | BI dashboards, reporting, analytics | AI agents, RAG systems, ML models, real-time inference |
| Data types | Structured (SQL, CSV, JSON) | Structured + unstructured (PDFs, emails, images, audio) |
| Processing model | Batch ETL/ELT on schedule | Batch + real-time streaming + event-driven pipelines |
| Storage | Relational databases, data warehouses | Lakehouse + vector stores + feature stores |
| Data quality focus | Schema validation, null checks, deduplication | Embedding quality, chunk coherence, label accuracy for AI |
| Governance | Access control, data catalog | + PII classification, model lineage, AI decision audit trails |
| Key skills | SQL, Spark, dbt, Airflow | + vector databases, embedding pipelines, MLOps, RAG infra |
The Databricks State of Data and AI 2026 Report found that 71% of data engineering teams are now explicitly tasked with building AI-ready infrastructure – up from 31% in 2023.
Organizations that built this capability proactively are deploying AI at three times the rate of those still working from analytics-era stacks.
The 6 Core Service Pillars of AI Data Engineering Consulting
A comprehensive data engineering consulting engagement in 2026 spans six capability areas. Not every organization needs all six immediately – but understanding the full scope helps you identify where your stack has gaps and where to invest first.
Pillar 1: Modern Data Architecture
Architecture decisions cover the foundational choices: lakehouse vs. warehouse vs. data mesh, cloud vs. on-premise vs. hybrid, and the integration pattern connecting source systems to the data platform. Decisions made at this layer constrain what is possible in every other pillar. Picking the wrong storage model for your AI workload profile means rebuilding it later.
Pillar 2: Data Pipeline Development
Pipeline development covers batch ETL/ELT, real-time streaming (Apache Kafka, Spark Streaming, Flink), and change data capture (CDC) for operational database replication.
For AI workloads, pipeline reliability and latency matter in ways they never did for BI. An AI agent making a credit decision on data that is 48 hours stale is not an AI agent – it is a time-delayed manual process.
Pillar 3: Data Quality and Governance
This pillar covers data lineage (tracking where every data point came from and how it was transformed), data observability (monitoring for anomalies and drift in production), PII detection and classification, and data catalog management.
For AI systems, governance here is directly connected to compliance audit requirements. You cannot demonstrate GDPR compliance for an AI decision without lineage that traces the decision back to its input data.
Pillar 4: Vector Store and RAG Infrastructure
Building the data infrastructure that enterprise RAG systems depend on: document ingestion pipelines, embedding model selection and hosting, vector database deployment (Pinecone, Weaviate, pgvector, Milvus), and retrieval quality optimization.
This is the fastest-growing area of data engineering work in 2026 and the one most traditional data engineering firms are not yet equipped to deliver.
Pillar 5: MLOps and Feature Engineering
MLOps consulting covers the operational layer for ML models in production: model versioning and registry, CI/CD pipelines for model deployment, feature store design and management, drift monitoring, and automated retraining triggers.
Without MLOps, ML models degrade in production unnoticed until something breaks. McKinsey’s State of AI 2025 found that organizations integrating data engineering and MLOps planning reduced production ML incidents by 60–70%.
Pillar 6: Data Platform Consulting
Data platform consulting covers selection, configuration, and optimization of the core platform stack: Databricks, Snowflake, BigQuery, Microsoft Fabric, or an open-source equivalent. Platform selection has long-term cost and scalability implications.
The right platform depends on your workload profile, compliance requirements, and in-house operational expertise. Choosing Databricks because it is popular is not platform consulting.
MLOps Consulting: Why Data Engineering and ML Production Are Inseparable
MLOps consulting has become a standard component of data engineering engagements for organizations running AI in production.
The connection is not optional – ML models are data artifacts, and their performance is determined by the quality, freshness, and consistency of the data they are trained and scored on.
What MLOps Covers in a Data Engineering Context
- Model versioning and registry: Tracking which model version is in production, what data it was trained on, and what evaluation metrics it achieved at deployment
- CI/CD for ML: Automating the testing, validation, and deployment of model updates – the same principle as software CI/CD, with data validation gates added
- Feature store design: Centralized storage for engineered features that ensures consistent feature computation between training and production inference
- Drift monitoring: Detecting when production data characteristics diverge from training data – the most common cause of unexplained model performance degradation
- Automated retraining: Triggering model retraining when drift thresholds are exceeded, with validation gates before production promotion
The integration point between data engineering and MLOps is the feature store and the data pipeline. When these are designed together from the start, the system stays aligned across training and inference. When they are designed separately and connected later, the mismatch causes most production ML failures.
Compliance-Grade Data Engineering for Regulated Industries
BFSI, healthcare, and manufacturing organizations need data infrastructure that satisfies GDPR, HIPAA, SOC 2, and for Vietnam-based operations, AI Law 134/2025/QH15. These requirements go well beyond access controls and extend into how data moves through pipelines, how AI systems log their data access, and how lineage is maintained for regulatory review.
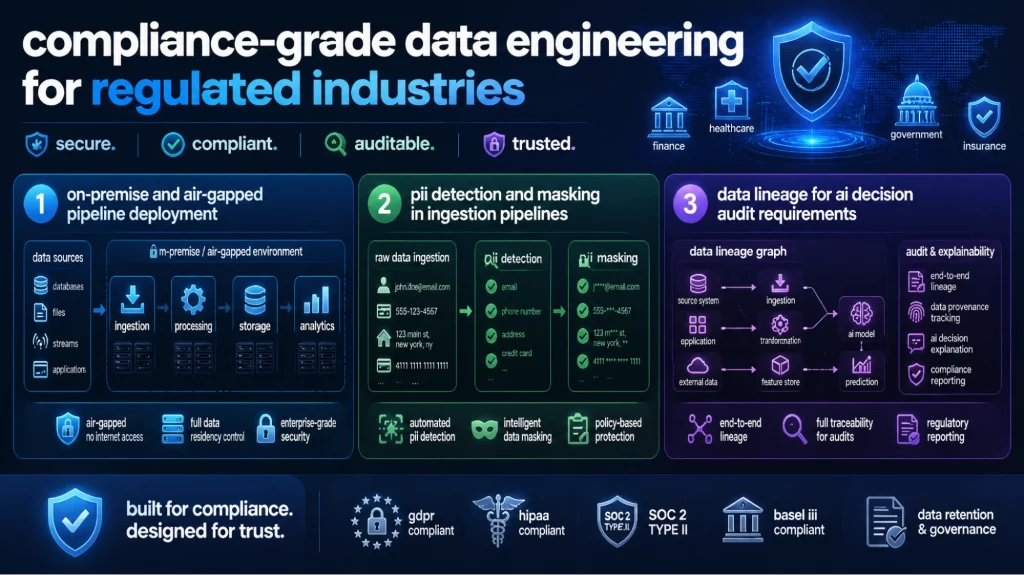
On-Premise and Air-Gapped Pipeline Deployment
Some data cannot move to public cloud infrastructure. Patient records, financial transaction data, and defense information must stay on controlled hardware. On-premise pipeline deployment keeps all processing within your network. Air-gapped infrastructure adds network isolation as an additional security layer.
AHT Tech designs and deploys on-premise stacks using production-grade tooling – Airflow, Spark, dbt, and vector databases – running on client hardware.
PII Detection and Masking in Ingestion Pipelines
PII must be identified before data enters your analytical or AI processing layer – not after.
Modern AI-ready data infrastructure includes automated PII detection at ingestion using NLP classifiers that identify names, email addresses, national IDs, and health identifiers, with configurable handling: masking for analytics use cases, tokenization for joinable data, or exclusion for highest-sensitivity fields.
Handling PII at ingestion prevents contamination of vector stores, feature stores, and model training sets.
Data Lineage for AI Decision Audit Requirements
GDPR Article 22 and HIPAA both require the ability to explain automated decisions and show what data contributed to them.
AI data lineage means demonstrating: which training data a model used, what features were computed from what source data, and what documents a RAG system retrieved when generating a specific response. Standard catalog tools capture warehouse lineage. AI lineage requires additional instrumentation at the model serving and retrieval layer.
How to Evaluate a Data Engineering Consulting Partner for AI Workloads
Not all big data consulting services are equipped for AI-ready infrastructure. The vocabulary has shifted, but many firms are still optimizing for the analytics era. Here is how to assess whether a partner can deliver what you need.
| Evaluation Criterion | What to Ask | Red Flag to Watch For |
| Vector store and RAG experience | Which vector databases have you deployed in production? On-premise or cloud? | Cloud-only answers, or no mention of vector stores at all |
| Platform flexibility | What stacks do you work with? Are you certified across multiple platforms? | Heavy bias toward a single vendor – Databricks-only or Snowflake-only |
| Compliance track record | Which regulated industries have you delivered for? Reference available? | No regulated industry clients, no mention of compliance architecture |
| MLOps capability | How do you connect data pipelines to model training and serving in production? | No MLOps capability or routes ML work to a completely separate team |
| Delivery model options | Do you offer project-based, dedicated team, and managed service models? | Only one delivery model offered – signals inflexibility |
AHT Tech brings 18+ years of enterprise infrastructure delivery and 250+ specialists across data engineering, AI, and compliance architecture. We work across Databricks, Snowflake, open-source stacks, and on-premise infrastructure. Vector stores and RAG pipelines are standard scope in our AI data engineering engagements.
Conclusion
AI-ready data infrastructure is the foundation every AI initiative depends on. Without clean, governed, pipeline-connected data, agents hallucinate, RAG systems return stale or irrelevant results, and ML models degrade in production without warning. Data engineering consulting services in 2026 build that foundation with AI workloads as the design target.
AHT Tech‘s data engineering practice covers the full stack: from legacy modernization through AI-native pipeline architecture, vector store deployment, MLOps integration, and compliance-grade governance for GDPR, HIPAA, SOC 2, and Vietnam AI Law 134/2025/QH15. We work with mid-market and enterprise clients across BFSI, healthcare, manufacturing, and logistics.
| Request a Data Infrastructure Assessment from AHT Tech. We evaluate your current stack against AI-readiness criteria, identify the gaps that are limiting your AI deployments, and deliver a prioritized remediation plan. Visit us and schedule a meeting for further collaboration. |
FAQs
What is the difference between data engineering and data science?
Data engineering builds and maintains the infrastructure that data scientists and AI systems use. Data engineers design pipelines, build data stores, and ensure quality and availability. Data scientists use that infrastructure to build models and derive insights. In most organizations, data engineering is the prerequisite that data science depends on – and the bottleneck when it fails.
What does AI-ready data infrastructure mean?
AI-ready data infrastructure is a data stack designed specifically to support AI workloads: real-time or near-real-time pipelines, vector storage for embedding-based retrieval, feature stores for ML model training and inference, and compliance-grade lineage and governance. It differs from analytics infrastructure, which optimizes for query performance on historical structured data.
How much does data engineering consulting cost?
A focused AI-readiness assessment and architecture design engagement runs $20,000–$60,000. A pipeline modernization with vector store deployment for RAG infrastructure runs $80,000–$250,000. A full enterprise data platform modernization with MLOps integration runs $300,000–$1M+. Dedicated team engagements are priced on a monthly retainer.
What is MLOps and why does it matter for data engineering?
MLOps is the operational practice for managing ML models in production. It connects to data engineering because model performance depends on data pipeline quality. Pipeline changes that alter feature distributions degrade model performance in ways that are invisible without drift monitoring. Teams that integrate data engineering and MLOps planning avoid this failure mode.
Can data pipelines be deployed on-premise for compliance?
Yes. On-premise deployment is standard practice for healthcare, financial services, and defense. Modern orchestration tools – Airflow, Prefect, Dagster – run on-premise. Vector databases – Weaviate, pgvector, Milvus – run on-premise. Technical constraints on scalability and maintenance overhead need to be part of the architecture design, not surprises discovered during operation.