

Enterprise RAG Solutions: What They Are, How They Work, and Why Generic LLMs Fall Short

TABLE OF CONTENT
What Is Retrieval-Augmented Generation (RAG)?
The Enterprise RAG Architecture: 5 Core Components
Building the LLM Knowledge Base: What Goes In and How It Stays Current
Enterprise RAG Use Cases That Are Running in Production
Compliance and Data Sovereignty: Why This Changes Everything for Regulated Industries
Build vs. Buy: Enterprise RAG Implementation Options
Conclusion

Ask a generic large language model what your refund policy says. It will give you a confident answer. It will probably be wrong, because your refund policy was never in its training data. Ask it the same question using an enterprise RAG solution that has indexed your internal documentation, and it will cite the exact clause. This is the core problem RAG solves: the gap between what a generic LLM knows and what your enterprise needs it to know. This guide explains enterprise RAG solutions – the architecture, the use cases, the compliance requirements, and the implementation decisions that determine whether the system actually works in production.
What Is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an AI architecture pattern that combines a large language model with a retrieval layer over your own data.
Instead of relying solely on training data, a RAG system retrieves relevant context from a verified internal knowledge base at query time, injects that context into the LLM’s input, and generates a response grounded in documents you control.
The result is an AI system that answers questions accurately using your specific policies, procedures, contracts, and knowledge – without confabulating information that does not exist in your records.
According to Gartner’s Generative AI Infrastructure Report 2025, RAG is now the most widely deployed GenAI pattern in enterprise environments, used in 62% of production GenAI deployments. The primary reason: it controls hallucination while enabling real-time data access, which fine-tuning cannot do.
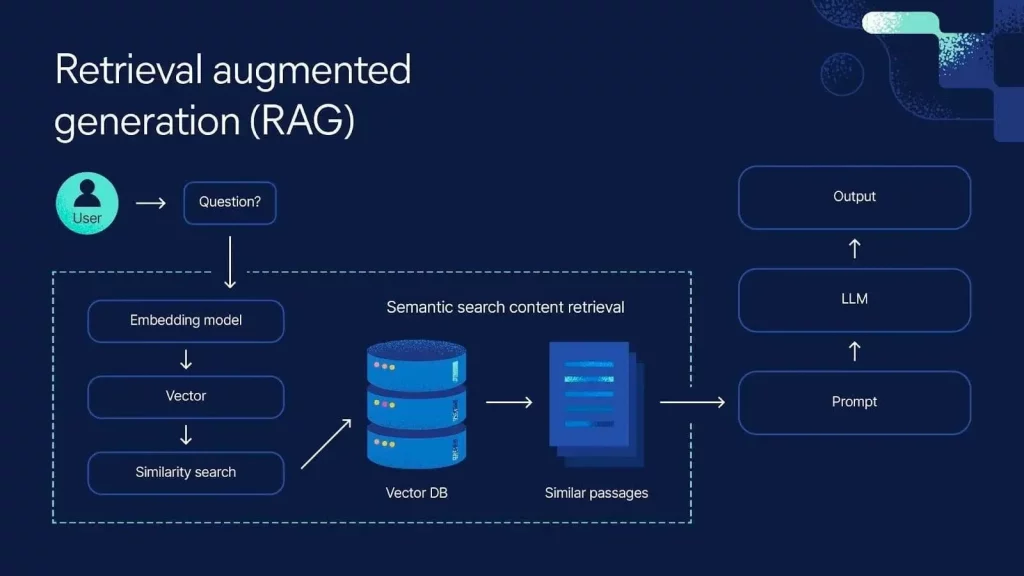
How RAG Works: The Four-Step Loop
- Query: User submits a question or an agent receives a retrieval trigger
- Retrieval: The system searches your vector database using semantic similarity to find the most relevant document chunks for this specific query
- Context injection: Retrieved chunks get inserted into the LLM prompt as grounding context
- Response generation: The LLM generates an answer based on the retrieved context and cites the source documents
RAG vs. Fine-Tuning: When to Use Each
| Dimension | RAG | Fine-Tuning |
| Use case | Questions over dynamic, frequently updated data | Teaching specialized vocabulary or response style |
| Data freshness | Handles real-time data via automated ingestion | Static – requires full retraining when knowledge changes |
| Hallucination control | Strong – grounded in retrieved sources with citation | Weaker – model can still confabulate domain-specific facts |
| Cost | Inference cost only, no training overhead | High training compute cost plus ongoing maintenance |
| Compliance audit trail | Full retrieval log available | No retrieval trace – decision is opaque |
| Deployment speed | Days to weeks for standard documents | Weeks to months including data prep and evaluation |
Most production enterprise deployments use RAG as the primary pattern and fine-tuning as a supplement for specialized language tasks. The combination gives you grounded factual responses and a consistent voice.
The Enterprise RAG Architecture: 5 Core Components
A production enterprise RAG solution is not a PDF reader plugged into a chat interface. It is a five-component system, and each component requires deliberate design decisions that will determine the system’s accuracy, speed, and compliance posture.
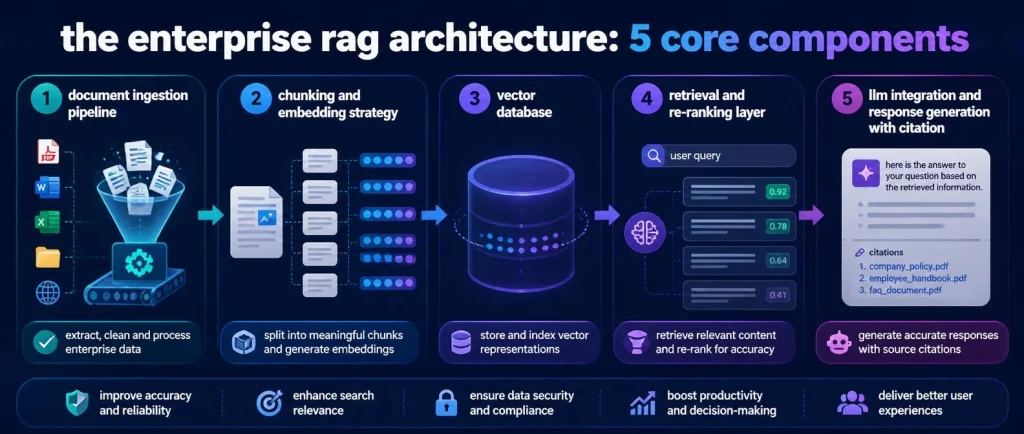
Component 1: Document Ingestion Pipeline
The ingestion pipeline extracts text from source documents, normalizes formats, and maintains update frequency. It needs to handle PDFs, Word documents, HTML pages, SharePoint libraries, database records, and structured data feeds.
Quality at ingestion determines quality everywhere downstream. A pipeline that introduces formatting artifacts or misses content produces a retrieval layer that returns garbage.
Component 2: Chunking and Embedding Strategy
Documents get split into chunks before embedding. Chunk size, overlap between adjacent chunks, and chunking logic – by sentence, by section, by semantic unit – directly affect retrieval quality.
Overlarge chunks retrieve too much irrelevant context. Undersized chunks lose the surrounding meaning that makes a passage interpretable. There is no universal answer; the right strategy depends on your document types and query patterns.
Component 3: Vector Database
The vector database stores your embedded chunks and enables semantic search. Common production options include Pinecone (managed cloud, fast setup), Weaviate (open-source, cloud or on-premise), pgvector (PostgreSQL extension, on-premise friendly, familiar operations model), and Milvus (open-source, optimized for high-scale deployments).
For regulated industries, on-premise vector database deployment is often a compliance requirement – no embedded data leaves your network.
Component 4: Retrieval and Re-Ranking Layer
Retrieval returns the semantically closest chunks. Re-ranking applies a secondary model to reorder those results by relevance to the specific query.
This two-stage approach consistently improves answer quality over vector search alone, especially for complex queries that require pulling evidence from multiple documents. Re-ranking adds latency but significantly reduces irrelevant context injection.
Component 5: LLM Integration and Response Generation with Citation
The LLM receives the retrieved context and the original query, then generates a response. For enterprise applications, this response must include source citations (which documents were retrieved and which chunks were used), a defined fallback behavior when no relevant context is found (the system should say ‘I could not find this in the knowledge base’ rather than inventing an answer), and confidence indicators where appropriate.
| AHT Tech builds enterprise RAG systems with on-premise vector stores, PII classification, document processing pipelines, and multi-LLM routing. Your data stays on your infrastructure. |
Building the LLM Knowledge Base: What Goes In and How It Stays Current
An LLM knowledge base is the curated, structured repository of enterprise documents that your RAG system queries. Its quality sets the ceiling on your system’s accuracy. No amount of clever prompting or improved retrieval logic can compensate for a knowledge base that is incomplete, outdated, or poorly organized.
What Belongs in an Enterprise Knowledge Base
- Internal policies, procedures, and standard operating procedures
- Customer contracts, agreement templates, and amendment history
- Product catalogs, specifications, and technical documentation
- Regulatory and compliance documentation specific to your jurisdiction and sector
- Historical knowledge base articles and resolved support tickets
- Research reports and domain expertise documents relevant to your industry
Metadata Tagging and Access Control by Role
Every document in your knowledge base needs metadata: document type, department, date, version, author, and access tier. This metadata serves two purposes. It enables filtered retrieval – returning only documents relevant to a specific department, region, or compliance classification.
It also enforces access control – ensuring that a customer-facing agent cannot retrieve an internally confidential pricing strategy, and that a field technician agent cannot surface HR performance data.
Enterprise knowledge management AI that ignores access control at the retrieval layer is not enterprise-grade, regardless of how the marketing positions it.
Keeping the Knowledge Base Current
A knowledge base that is not updated produces confident wrong answers about things that changed last month. Automated ingestion pipelines monitor your source document repositories – SharePoint, Confluence, document management systems – and re-embed updated documents as they change.
For high-frequency updates, event-driven triggers replace batch processing. The pipeline should include a change-detection mechanism that flags what was updated and when, so your compliance team can audit the knowledge base state at any time.
Enterprise RAG Use Cases That Are Running in Production
These enterprise RAG solutions are deployed in regulated industries. Each targets a specific high-frequency knowledge retrieval problem where generic LLM responses would be unreliable or unacceptable.

Financial Services and Insurance
- Regulatory compliance Q&A: Internal agents answer compliance questions grounded in your current regulatory documentation – not public LLM training data that may be 18 months stale
- Product knowledge agents: Customer-facing agents retrieve from your current product catalogs, rate sheets, and policy terms – cited, not hallucinated
- Claims reasoning support: Retrieve relevant policy terms and settlement precedents to support claims adjudication decisions
Healthcare
- Clinical protocol retrieval: Clinician-facing agents surface relevant clinical guidelines and institutional protocols for specific patient presentations
- Drug interaction checking: RAG over your institutional formulary and interaction databases – grounded in your hospital’s current medication policies, not generic web data
Manufacturing, Legal, and Retail
- Maintenance manual lookup: Field technicians query equipment maintenance procedures via natural language against your technical documentation library
- Contract review support: Legal teams retrieve relevant clauses, precedents, and obligations from their contract archive for comparison and review
- Product catalog agents: Customer-facing agents answer product questions by retrieving from your current inventory and specification database
Compliance and Data Sovereignty: Why This Changes Everything for Regulated Industries
Enterprise knowledge management AI in regulated industries cannot use standard cloud-hosted RAG without additional data controls.
The requirements vary by framework, but the principle is consistent: enterprise data cannot reside on infrastructure you do not control, and every access event must be auditable.
On-Premise Vector Store Deployment
On-premise RAG means your vector database runs on your own servers or private cloud. No embedded document chunks, no retrieval queries, no LLM prompts, and no responses travel to an external API.
This is the standard requirement for air-gapped environments in defense, certain banking environments, and healthcare organizations where patient data governance requirements are explicit.
AHT Tech deploys on-premise vector stores using Weaviate, pgvector, and Milvus depending on scale, query volume, and integration requirements.
PII Classification in the Ingestion Pipeline
PII must be identified and handled before documents are chunked and embedded. AI document processing services at the ingestion layer use NLP classifiers to detect names, email addresses, national IDs, health identifiers, and financial account numbers.
PII found in source documents gets redacted at embedding time, tagged with access restrictions, or excluded from the knowledge base – depending on your compliance framework and the intended access population.
Handling PII at ingestion is far safer than filtering at retrieval; by retrieval time, the data is already in your vector store.
Audit Trail Requirements
A compliant enterprise RAG system logs every retrieval event: what query triggered it, which document chunks were returned, which document version was active at retrieval time, and what LLM response was generated.
This log is the evidence chain required for GDPR data access requests, HIPAA audit reviews, and SOC 2 compliance attestations. For Vietnam AI Law 134/2025/QH15, the logging requirement extends to AI-assisted decisions that affect individuals.
Build vs. Buy: Enterprise RAG Implementation Options
| Approach | What It Provides | Best For | Key Limitation |
| Cloud RAG-as-a-service (AWS Bedrock, Azure AI Search) | Managed vector store + retrieval, fast setup | Low-compliance, public or semi-public data | Data leaves your infrastructure; customization limited |
| Open-source stack (LangChain + self-hosted vector DB) | Full flexibility, no vendor dependency, on-premise capable | Engineering-heavy teams with compliance requirements | High maintenance burden, requires ML infrastructure expertise |
| Managed enterprise RAG development (AHT Tech) | Full-stack custom build with compliance layer, on-premise deployment | Regulated industries, complex documents, data sovereignty | Higher initial cost; vendor dependency on delivery partner |
| In-house build | Full control, no external dependencies | Organizations with 10+ ML engineers | $400k–$1.5M cost; 12–18 months to production |
IDC research shows that knowledge workers spend an average of 9 hours per week searching for information they either cannot find or are not sure they can trust.
Enterprise RAG systems reduce this to minutes for commonly-queried information types – a gain that compounds across a 1,000-person organization into thousands of recovered hours per month.
Conclusion
Enterprise RAG solutions are the infrastructure layer that makes LLMs usable on your data – reliably, verifiably, and within your compliance boundary. Generic LLMs are a starting point. Enterprise RAG is what makes AI answers trustworthy enough to act on in a regulated environment.
AHT Tech builds enterprise RAG systems with private vector stores, PII classification, compliance-first architecture covering GDPR, HIPAA, SOC 2, and Vietnam AI Law 134/2025/QH15, and multi-LLM routing via our AI Hive platform. We deploy on your infrastructure, not ours. Your documents, your vector store, your audit trail.
| Discuss with AHT Tech experts about your enterprise RAG requirements. Approach our Enterprise RAG & Knowledge Engineering solution to see our full service scope and delivery approach. |
FAQs
What is the difference between RAG and fine-tuning an LLM?
RAG retrieves context from your knowledge base at query time and injects it into the LLM prompt. Fine-tuning trains the model weights on your data. RAG handles frequently updated data better and provides a retrieval audit trail. Fine-tuning is better for specialized vocabulary or consistent response style. Most production systems use RAG as the primary pattern, fine-tuning as a supplement.
Can enterprise RAG be deployed on-premise?
Yes. On-premise RAG uses a self-hosted vector database, a locally deployed embedding model, and either a self-hosted LLM or an LLM API with no-egress data controls. This architecture is standard for regulated industries where document data cannot leave the network perimeter.
How do you prevent hallucination in enterprise RAG systems?
Most RAG hallucination comes from poor retrieval quality (wrong documents returned), insufficient retrieved context, or LLM over-generation beyond what the context supports. Mitigation requires tuning chunk size and embedding strategy, adding a re-ranking layer, setting a confidence threshold for answers, and implementing a defined fallback when no relevant context is found.
What vector database should I use for enterprise RAG?
For managed cloud: Pinecone for fast setup. For on-premise: Weaviate and pgvector are most widely deployed. For very large scale: Milvus for query volume performance. Choice depends on your deployment model, query volume, compliance requirements, and in-house database expertise.
How much does enterprise RAG implementation cost?
A managed cloud RAG setup for non-regulated use cases runs $20,000–$60,000. A custom enterprise RAG system with on-premise deployment and compliance layer runs $80,000–$300,000. Large-scale multi-department RAG deployments run $300,000–$1M+.